
OpenAI has once again raised the bar with the introduction of its new GPT-4o flagship model (“o” for “omni” indicating this model’s excellent audio-visual performance) which can reason across various media and modalities, including audio, vision, and text in real-time. According to Mira Murati, Chief Technology Officer (CTO) of OpenAI, “We’re looking at the future of interaction between ourselves and the machines,” and “We think that GPT-4o is really shifting that paradigm into the future of collaboration, where this interaction becomes much more natural.”
OpenAI stated that the model is free with usage limits for all users through both the GPT app and the web interface. As this model rolls out over the next few weeks, users who subscribe to OpenAI’s paid tiers, which start at $20 per month, will be able to make more requests. GPT-4o is not just an upgrade; it represents a significant leap forward in AI technology, embodying years of research, fine-tuning, and OpenAI’s commitment to innovation and advancement. Unlike its predecessors, GPT-4o boasts a multifaceted approach, seamlessly integrating text, speech, and video processing capabilities into a single, unified model.
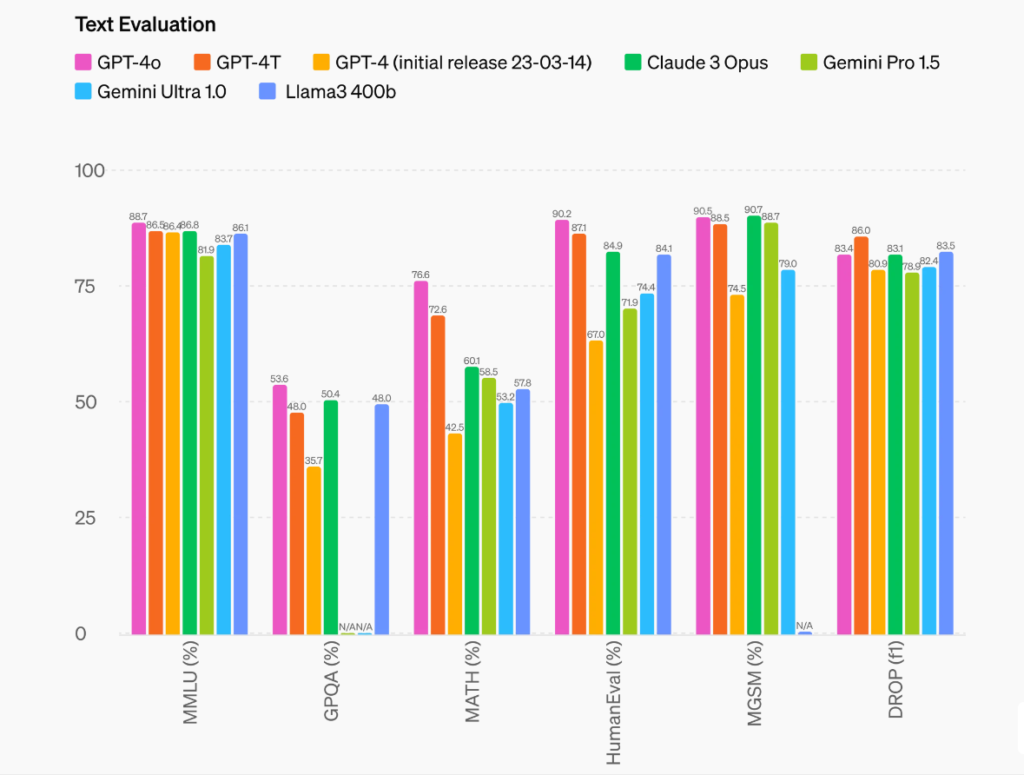
Model Evaluations: GPT-4o sets a new high score of 88.7% on Measuring Massive Multitask Language Understanding (MMLU) (general knowledge questions).
Breaking Down the Features: What Sets GPT-4o Apart
One of the most striking features of GPT-4o is its lightning-fast response times. With latency as low as 232 milliseconds, GPT-4o delivers near-instantaneous feedback, blurring the lines between human and machine interaction. Below is a video demonstration of this realtime responsiveness and translation by Mira Murati.
This feature not only enhances user experience but also opens up new possibilities for applications in various industries.
In a bid to broaden its chatbot usage, OpenAI has also launched a desktop version of ChatGPT with an updated user interface and GPT-4o coding assistant that acts as your coding buddy and can also interact on code bases, see both the outputs and everything going on in your computer as you code.
A demonstration included two GPT-4os engaging in a song, resembling a highly enhanced rendition of virtual assistants like Alexa or Siri.
At the heart of GPT-4o lies its remarkable ability to seamlessly solve math problems as seen below
Another key feature is the Interview Prep with GPT-4o which can tailor interactions more closely to the user’s needs.
It’s able to recognize emotions through breathing and other visual cues.
In addition to its text and voice capabilities, GPT-4o’s vision and Be My Eyes accessibility features are particularly impressive. This model demonstrates the ability to respond to inquiries regarding images or desktop screens, paving the way for potential applications such as live event explanations in the foreseeable future.
Safety and Ethics
OpenAI is prioritizing safety and alignment with human values in GPT-4o. They’ve incorporated human feedback and expert advice, along with lessons learned from real-world use of previous models, to improve safety measures. Alongside its preparedness framework, GPT-4o even assisted in safety research by helping generate training data and refine safety mechanisms. This ongoing process ensures GPT-4’s behavior is continuously monitored and improved as more people interact with it.
In conclusion, GPT-4o is still under development, but it gives us a glimpse of a future where AI seamlessly integrates into our daily lives. From helping us learn new things to sparking our creativity, to helping developers, the possibilities are endless. This model will extend to Enterprise customers and eventually to free users of ChatGPT and this is just the beginning of the generative AI industry.


