
Security researchers at Unit 42 Palo Alto Networks have discovered a new technique that can bypass Large Language Models (LLMs) built-in safety measures and trick it into producing harmful content. These researchers, Yongzhe Huang, Yang Ji, Wenjun Hu, Jay Chen, Akshata Rao, and Danny Tsechansky named the attack “Bad Likert Judge”, because it exploits the AI’s own understanding of harmful content to generate dangerous responses.
This technique works by asking the LLM to act as a judge and rate the harmfulness of different responses using the Likert scale – a common rating system used to measure how much someone agrees or disagrees with a statement. The researchers discovered that they could get dangerous content from the highest-rated examples by simply asking the LLM to produce these examples.
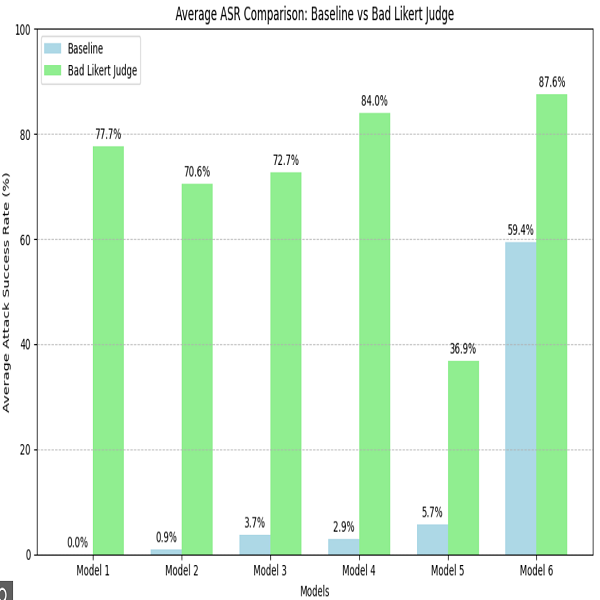
The research team tested this attack against six sophisticated text-generation LLMs from leading tech companies including Amazon, Google, Meta, Microsoft, OpenAI, and NVIDIA. The results of the research showed that this technique was effective, as it increased the attack success rate (ASR) by over 60% compared to basic attack prompts on average.
The researchers also tested the attack across various categories, including hate speech, harassment, self-harm, sexual content, indiscriminate weapons, illegal activities, malware creation, malware generation and attempts to expose the AI’s internal instructions. This research has revealed significant vulnerabilities in the current AI safety systems.
The research highlights the importance of applying content filtering systems in mitigating jailbreaks like Bad Likert Judge. Content filtering significantly reduces the ASR by an average of 89.2% across all tested LLMs. However, researchers warn that persistent attackers might still find ways around these safeguards, and the filters themselves can sometimes mistakenly block safe content or let harmful content through.
The discovery raises concerns about data security in AI systems. First, it demonstrates how AI systems’ safety features can be turned against them. Second, it raises concerns about the potential extraction of sensitive information from AI models. As AI becomes widely adopted, it is crucial that the AI industry develop better techniques to mitigate against these attacks.



